Randomness in Language Models
Current language models use temperature sampling to introduce randomness in output stage, which alters the learned distribution from pre-training by increasing entropy. However, recent study on RL shows that the policy entropy and downstream performance has a clear correspondance:
$$R = -a\exp H + b$$
where $H$ is the policy entropy and $R$ is the downstream performance. This contradicts with the motivation of temperature sampling.
Simply add a random string?
What if we just simply add a random string before the input as a randomness, and always use greedy decoding? Call it hash conditioning.
For example:
Normal prompt: "Solve this with minimal code length." →
Hash conditioning: "<ask289a12> Solve this with minimal code length."
The following is a jumping stair problem from leetcode, I sent to gemini 2.5 pro with the above prompt and see difference:
g=len(nums)-1
for i in range(len(nums))[::-1]:
if i+nums[i]>=g:g=i
return g==0m=0
for i,n in enumerate(nums):
if i>m:return False
m=max(m,i+n)
return TrueTry it yourself: Paste code below to count characters (excluding spaces and newlines)
We can see the one with hash conditioning does have less length!
Let's try on more models with different settings, comparing temperature sampling and hash conditioning.
Experiment
Coding problems: Human Eval
At first, set a relative small fixed temperature $T=0.2$ and fixed hash string length $L=5$. Compare 3 model's performance by human-eval (OpenAI).
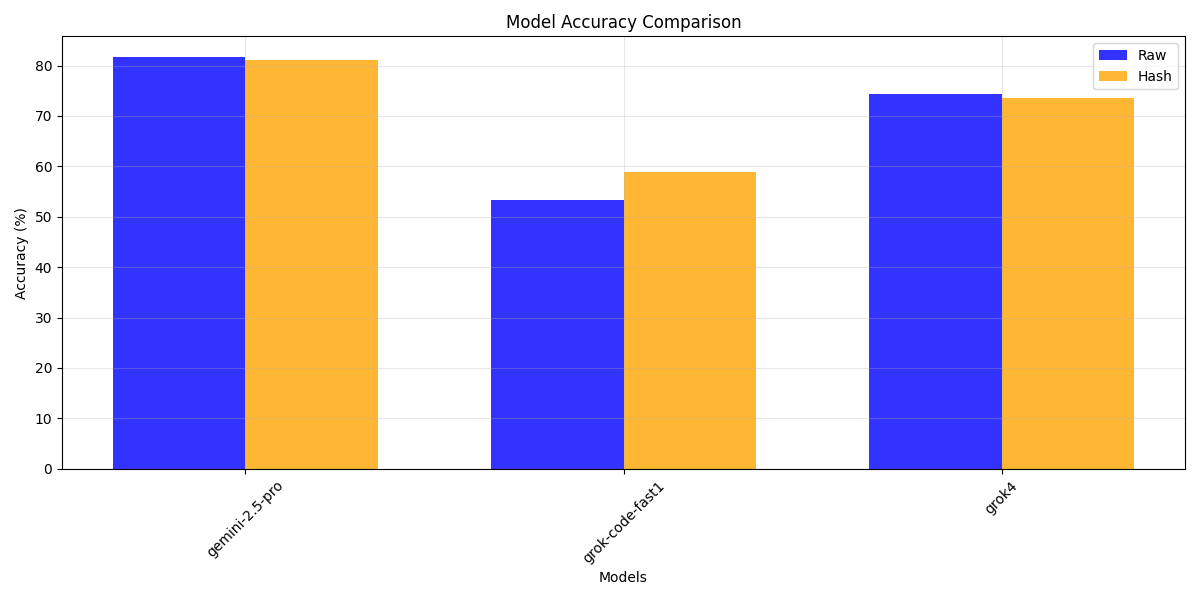
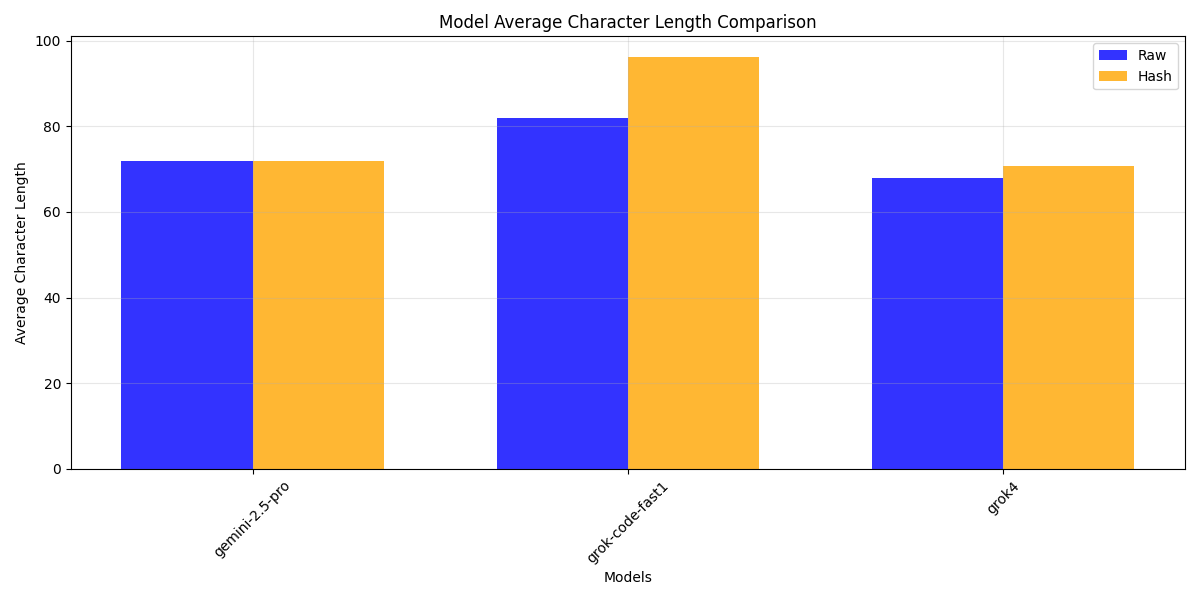
Accuracy is a little better, but average characters is more. Another thing is larger model is more robust to the additional string.
This might due to the effect of previous string on the latter tokens' representation, especially on reasoning problems this disadvantage is magnified.
How about knowledge testing problems?
GPQA-diamond: knowledge
Make the experiment setting more rigorous: compare
- different temperature sampling + majority voting
- different hash string length + majority voting
The 2 figures are results for gemma-3-27B and gemma-3-12B.
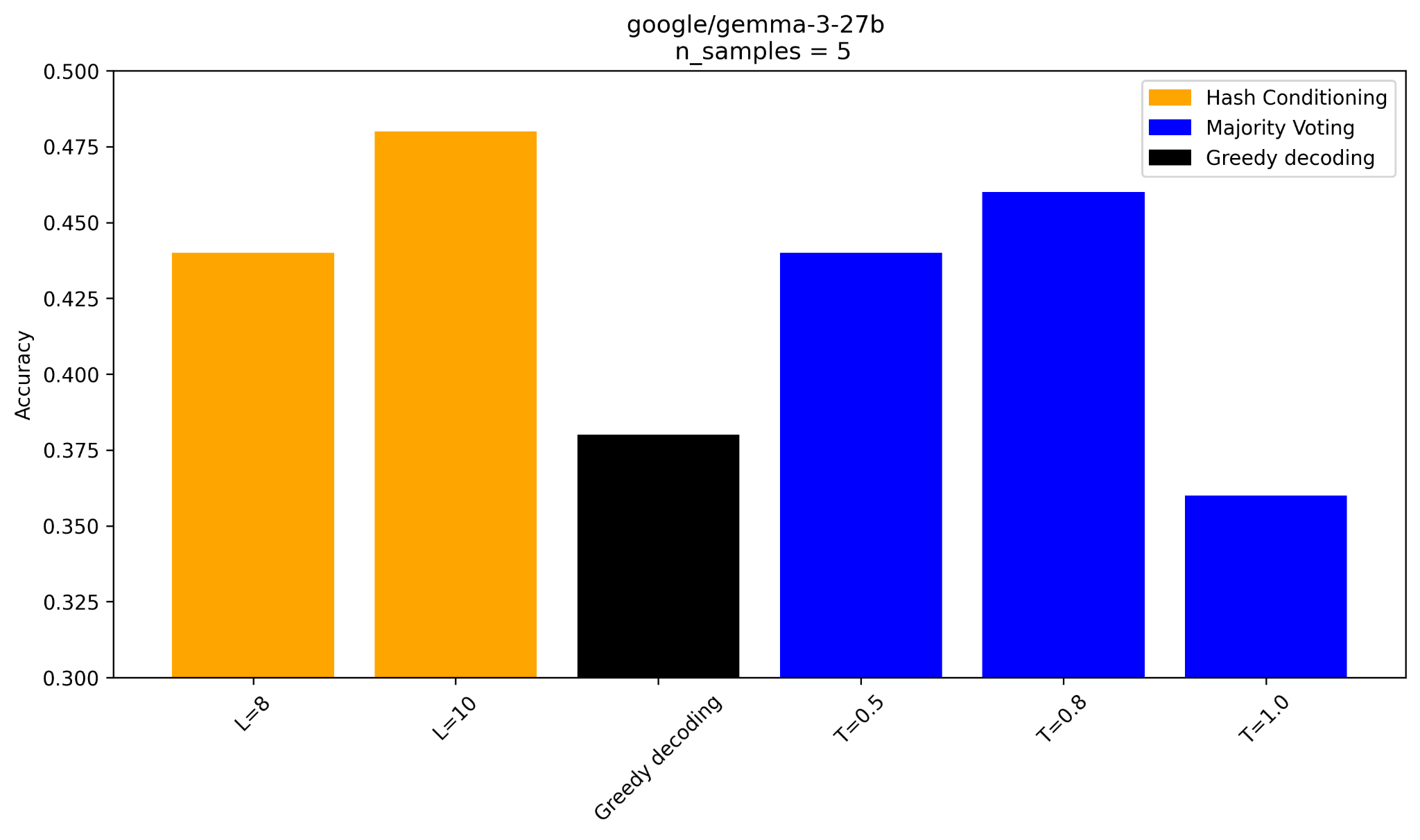
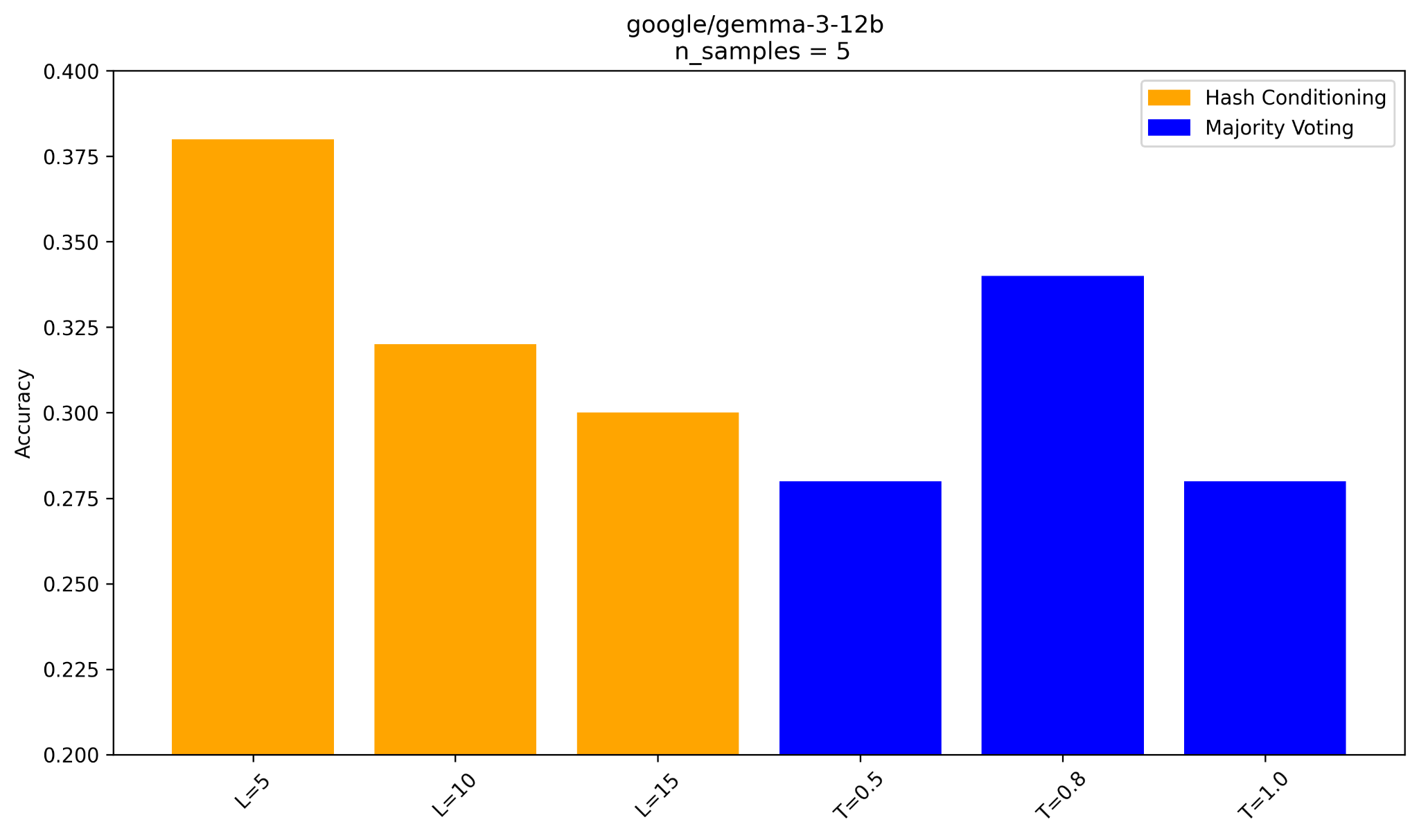
Looks good: the 2 models here can benefit from hash conditioning compared to other 3 temperature settings.
AIME: reasoning ability
From the toy experiment before, one may concern the disadvantage of hash conditioning on reasoning problems. Let's see if it is true on the above models:
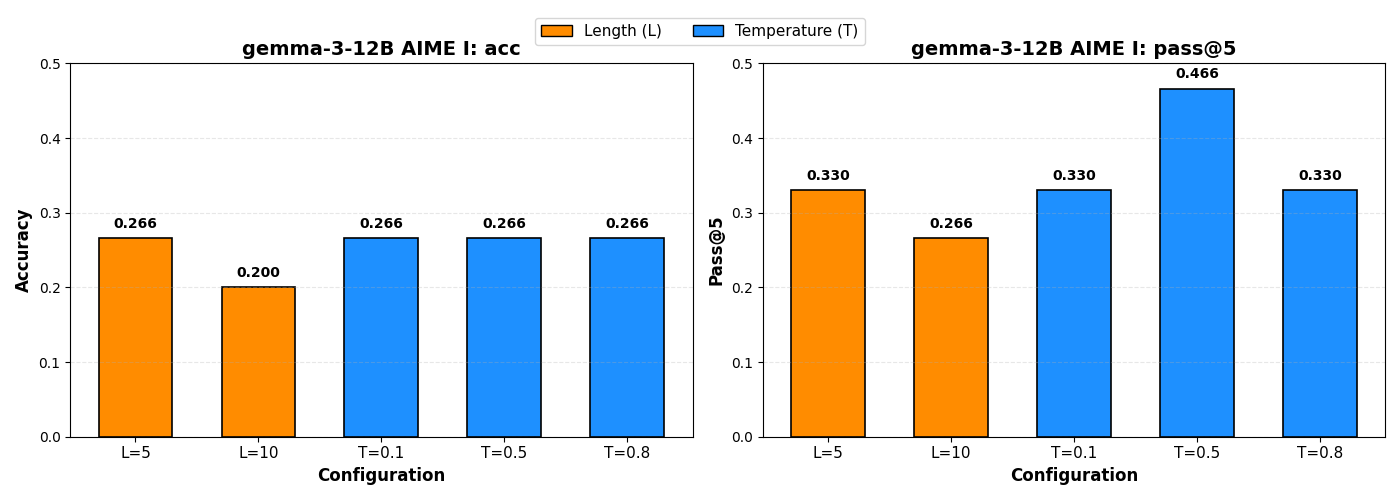
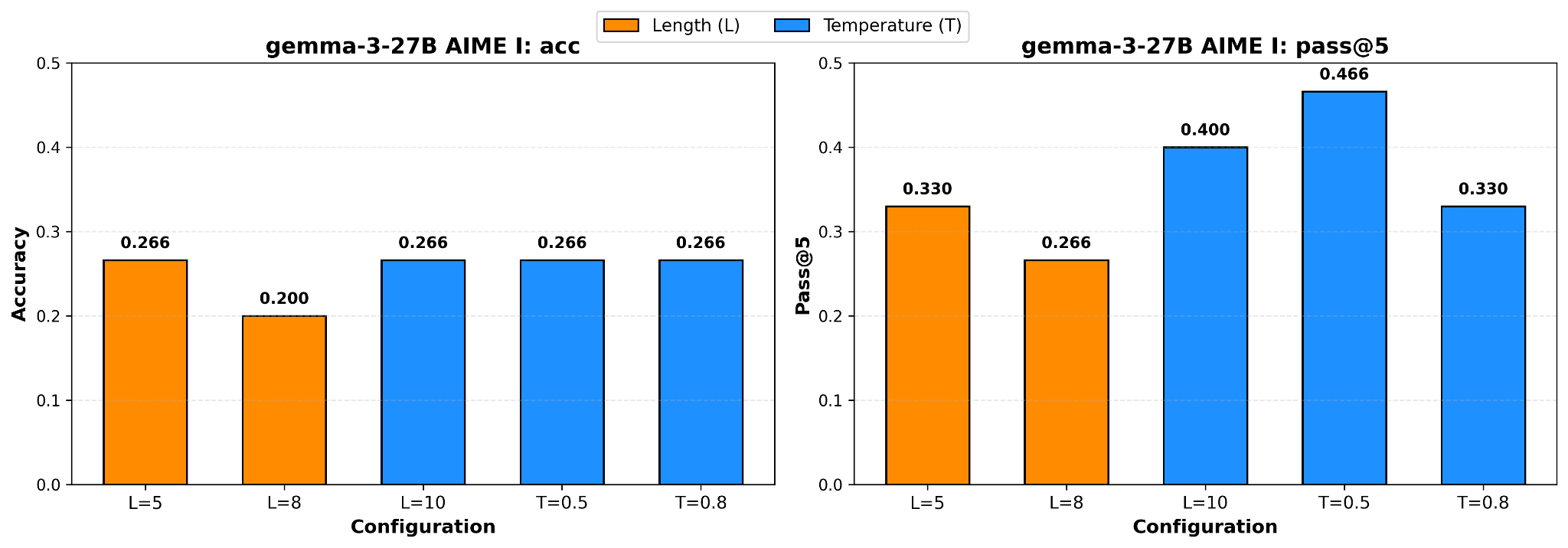
The figure does prove the concern: condition the whole reasoning trajectory on hash string is a bad idea, in comparison, temperature sampling does not change the representation of tokens.
Reddit joke: diversity
Temperature sampling makes output more diverse, can hash conditioning achieve this?
Testing diversity on single-choice problems like GPQA/AIME or coding problems is not a good idea. How about jokes? Can model tell different jokes by hash conditioning?
Compare diversity by
- The cosine distance between 5 text-embedding of generated jokes, according to hash conditioning and temperature sampling, respectively.
- LLM-as-a-judge: set the standard joke in the dataset as reference, let claude-3.7-sonnet judge the 5 jokes generated by hash conditioning and temperature sampling, respectively.
The following is the average score of hash conditioning and temperature sampling:
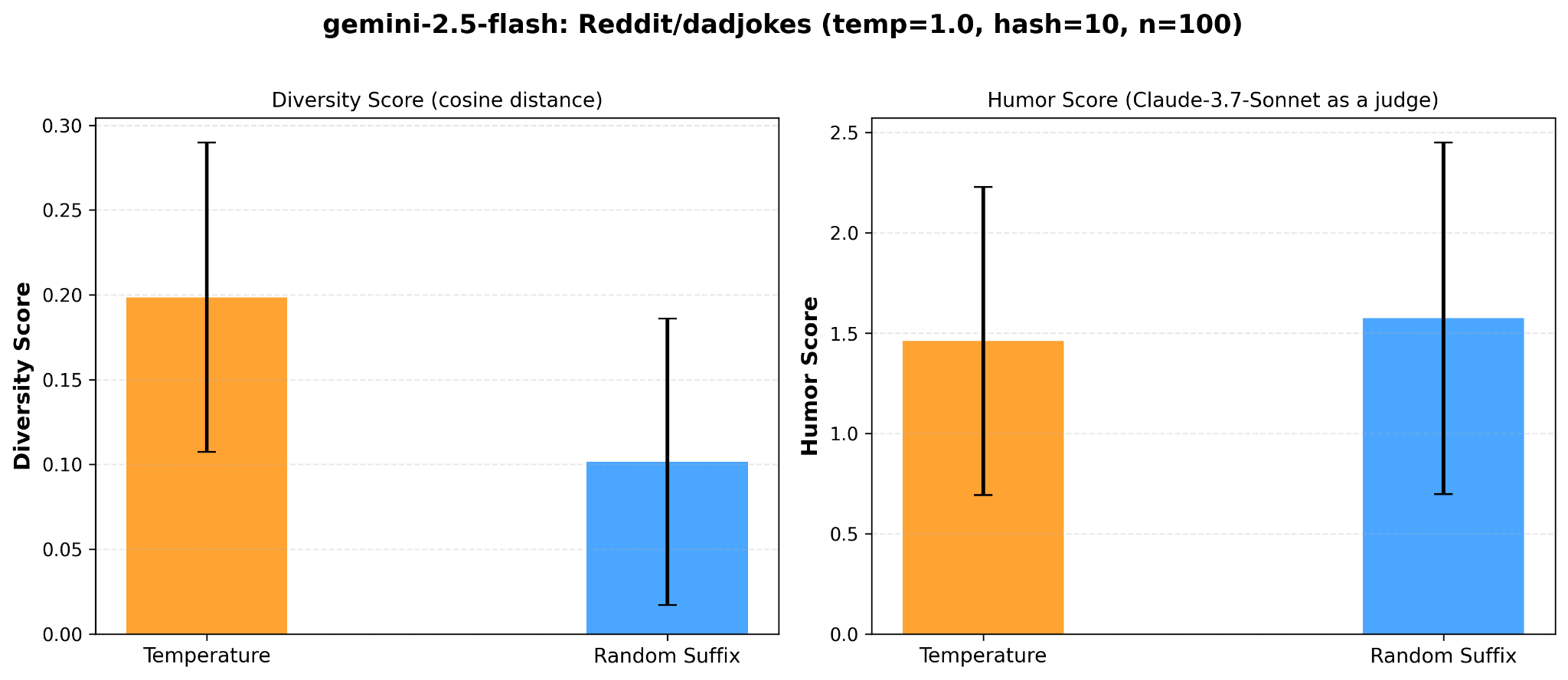
Despite the high variance, one can still conclude that hash conditioning does not give a more diverse distribution.
Summary
Adding a random string before the prompt and use greedy decoding is not a good idea, obviously:
- In pre-training data, no such pattern exist.
- It "perturbs" the representation of downstream tokens, leads to poor reasoning ability.
In comparison to temperature sampling, which alters a learned distribution after it is produced, hash conditioning instead tries to produce a different distribution by adding random string.
Although the experiment result does not conclude that hash conditioning is better than temperature sampling, we can still think of the problem:
"Is there any better way to introduce diversity or randomness into language model?"
Other ways of introducing randomness
Diffusion language model learns the joint distribution of sequence, instead of auto-regressive distribution. By controlling the noise scheduler, one can inject different types of noise.
However, disadvantages like the slow sampling speed and high training complexity is also true.
One might think how to combine the advantage of diffusion language model and auto-regressive language model, please wait for the next blog/pub!