Visualizing model's thought
Hypothesis
for classification tasks performed by in-context learning, model assign inputs belongs to different labels onto distinct, different manifolds to form clusters.
Task setting: a simple classification task with 10 labels.
$$\text{Label}(x) = \text{alphabet}(x \; \text{mod} \; 10)$$
where $x$ is an integer input, and $\text{alphabet}(n)$ returns the n-th letter in English alphabet. For example, $1:A, 11:A, 2:B, 22:B, ...$
Visualizing the hidden state of model
The context is : "1:A, ..., 101:A, 2:B, ..., 102:B, 3:C, ..., 103:C, 4:D, ..., 104:D, 111:".
I extract the hidden state of all number tokens in layer 1, 14, 32 for meta llama3-8b, and perform t-SNE on them to visualize. Blue, orange, green, red are numbers with label A, B, C, D, that is, end with 1, 2, 3, 4:
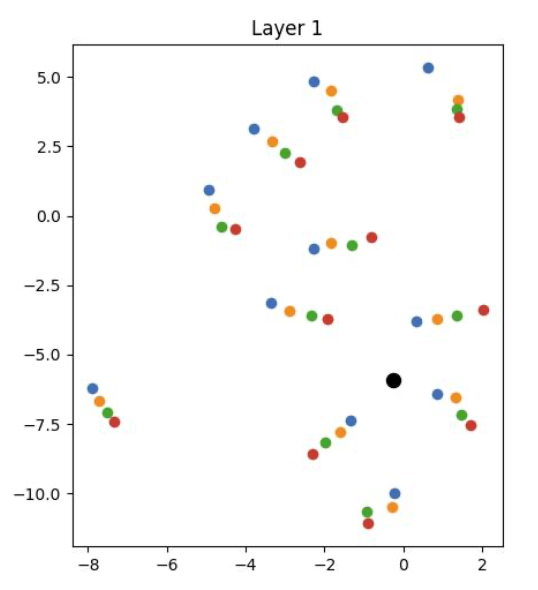
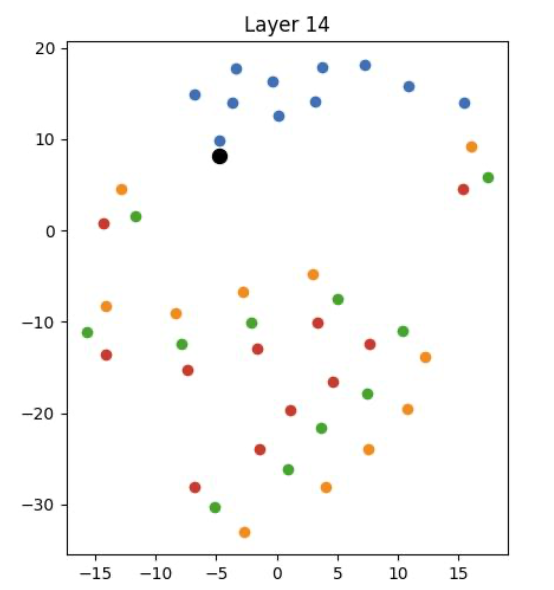
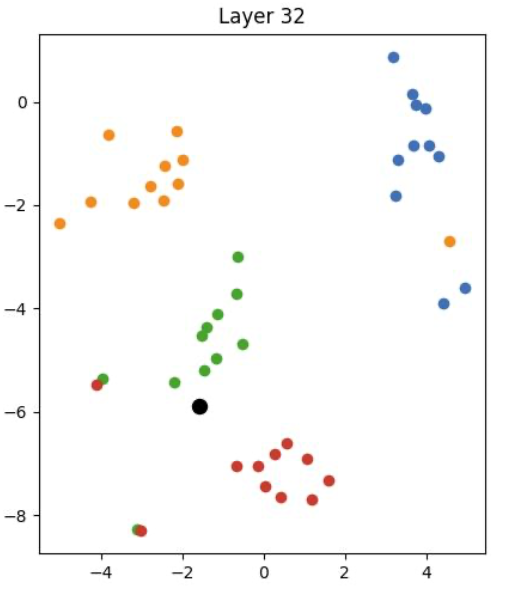
As we can see, at the very first layer, the representations of different labels are mixed together. As we go deeper into the network, the model gradually separates the representations of different labels, forming distinct clusters by the final layer. This suggests that the model is organizing the input data into different clusters, supporting our hypothesis.
How much is the clusters separated?
One may solve the problem with one-dimensional non-linear representation. Let's check the effective dimension of model's representation.
$$\alpha = \frac{\left(\sum_{i}\sigma_{i}^{2}\right)^{2}}{\sum_{i}\sigma_{i}^{4}},\quad\mathrm{where}~X=U\Sigma V^{T}, \sigma_i \;\text{is the i-th singular value}$$
Let's see how the effective dimension changes across layers
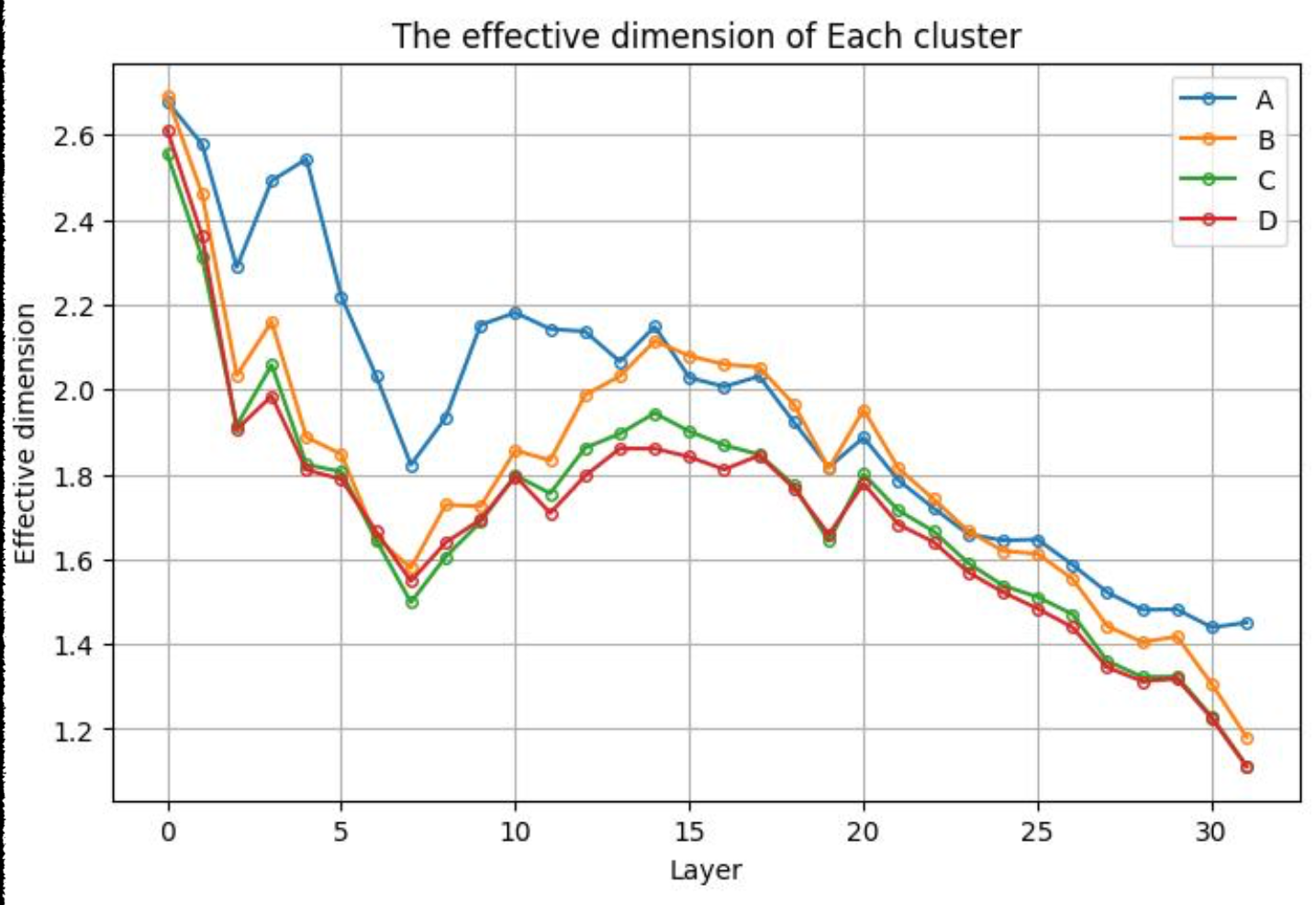
The effective dimension is about 1.4, which meets with the intuition that the problem should be solved with one dimension representation.
Is the representation linear separable? Let's figure out:
$$S^{\star}(A):=\operatorname*{sup}_{\|u \|=1}\frac{1}{n}\left[\sum_{i\in A}\mathbb{I}(u^{T}h^{(i)}>0)+\sum_{i\ne A}\mathbb{I}(u^{T}h^{(i)})\right] $$
The separability in the 2 dimensional-space should be large, according to the effective dimension we had before. Let's check it by first project the representation on the first 2 right- singular vectors
$$h^{(i)} = (x^{(i)} \cdot v_1, \; x^{(i)} \cdot v_2)$$
And plot the average separability score $S^{\star}$ between clusters
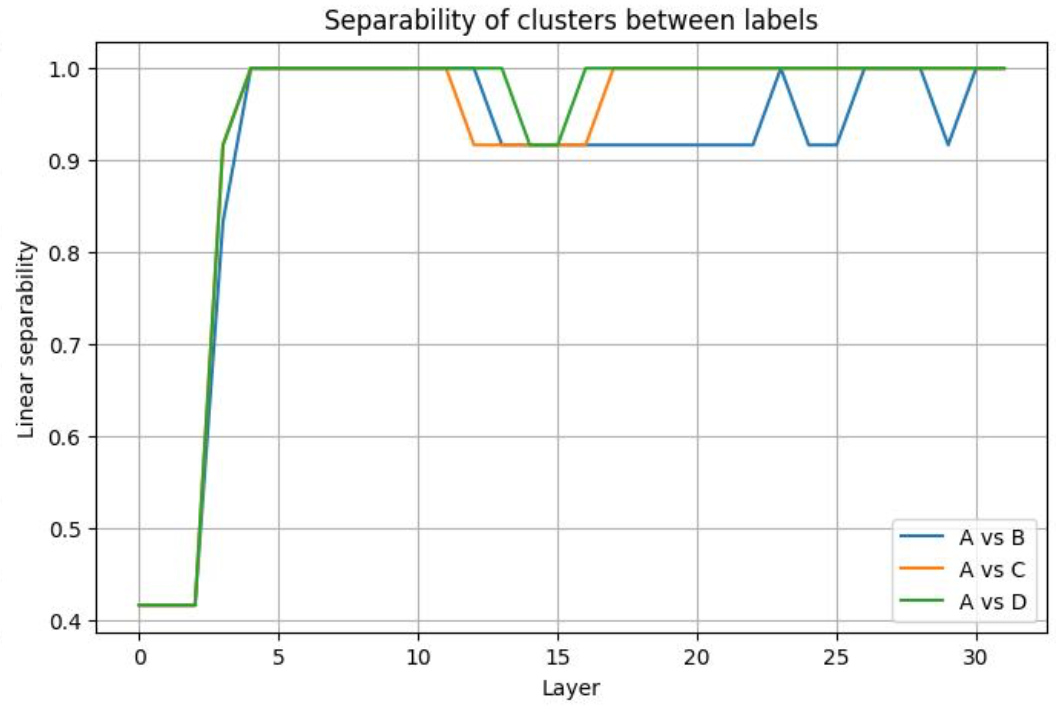
The figure clearly demonstrate that the representation projected to the first two right singular vectors has a high separability score, indicating that the clusters are well-separated, which meets with the hypothesis, and the model's perfect performance on the task.
Other visualization
Here are some other visualizations. For example, how does model represent 7 days in a week, or words discribing size like "big", "small"?
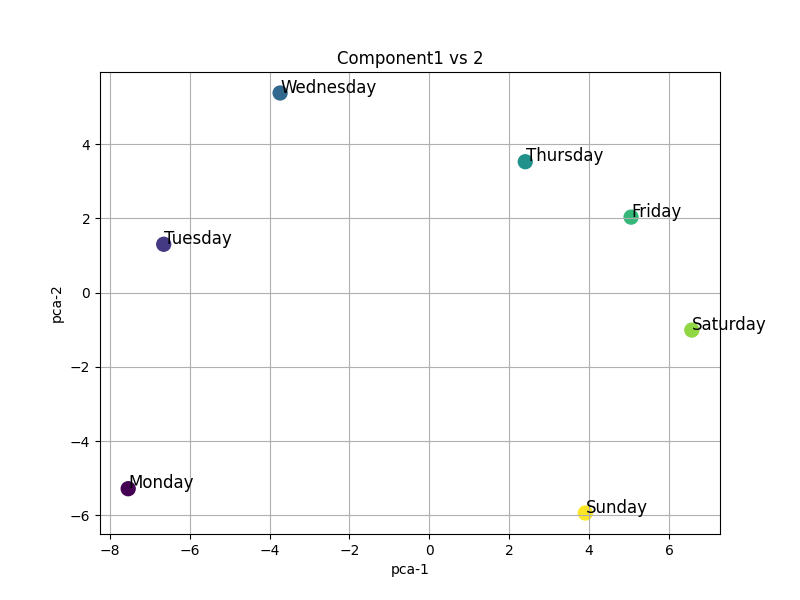
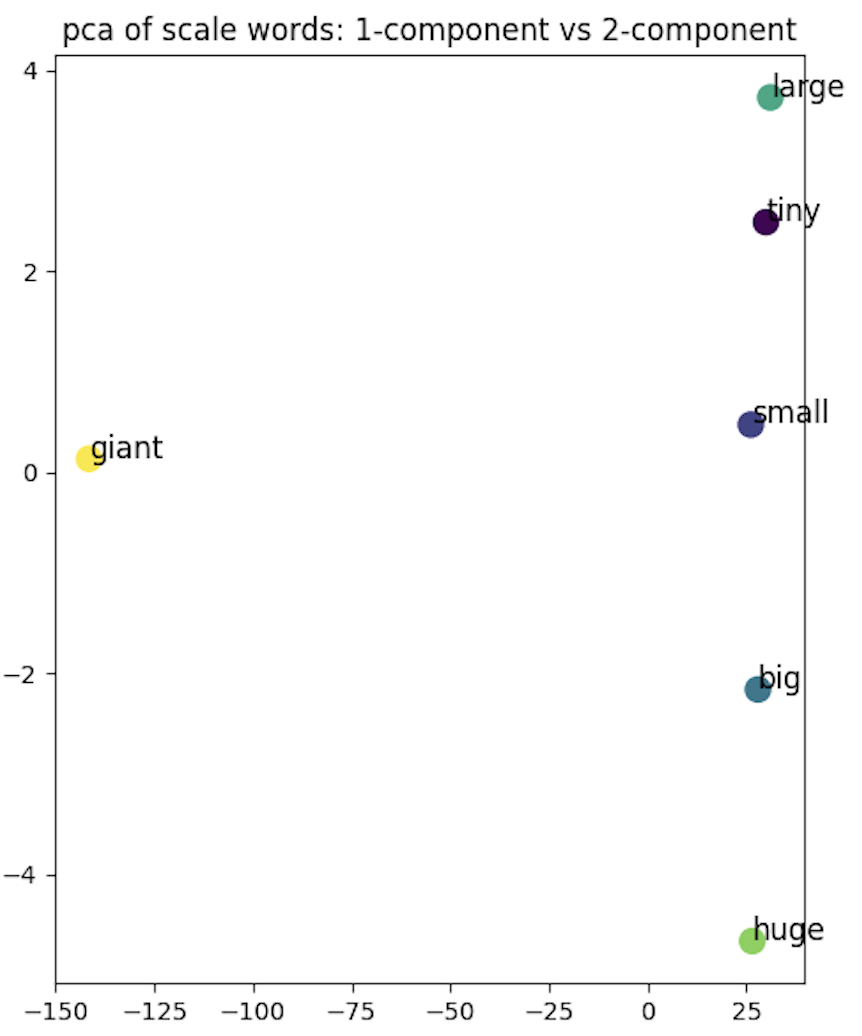
The above visualization shows that, model can learn the geometry of semantics, or in-context. If one thinks about the relationships between words, it becomes clear that the model is capturing not just the meanings of individual words, but also their contextual relationships.
The representation of language model is still quite mysterious. Back to 2023, linear representation hypothesis was proposed. After that, researchers found that there are many non-linear representations, like circles, helix. Recently, some researcher proposed a new perspective of treating features, from a geometry perspective. However, there is still a lot of definition on features in the field of mechanistic interpretability.
This blog simply visualized some toy cases, aiming to let readers have an intuition about representations.